

От товара к предложению: как Ozon учитывает цену и доставку в ранжировании

Всем привет! Меня зовут Станислав Ким, я ML-разработчик в команде качества поиска Ozon. В этой статье расскажу, как мы перешли от ранжирования товаров к ранжированию предложений, внедрили «матрицу памяти» для переноса статистики и получили +0,9% к GMV на пользователя.
Представьте простую ситуацию. Вы продавец электроники. Выводите на Ozon новую модель робота-пылесоса. Чтобы ворваться на рынок, вы ставите цену на 20% ниже конкурентов и отгружаете партию на ближайший склад, чтобы доставка была «завтра». Логика подсказывает: алгоритмы увидят выгодное предложение (дёшево + быстро), подкинут товар в топ, и продажи взлетят.
Реальность: проходит день, два... а товар висит на 5-й странице выдачи. Потому что для алгоритма ранжирования ваш пылесос — «чистый лист». У него нет истории продаж, нет кликов, нет отзывов. Рядом в топе конкуренты — они дороже, доставка дольше, но у них есть история: тысячи заказов за прошлый год. Алгоритм «любит» их за накопленную статистику, а ваше выгодное предложение игнорирует — он просто не знает, чего от него ждать. В индустрии эта проблема называется cold start — и с ней сталкиваются все крупные маркетплейсы.
Мы поняли, что нужно менять саму парадигму. Наш лозунг: ранжировать не абстрактную карточку товара с её прошлым, а конкретное предложение с его условиями здесь и сейчас.
Не только наша проблема: cold start в индустрии
Amazon выделила cold start как ключевой вызов для поиска ещё в 2016 году. Новые товары ранжировались плохо даже при высокой релевантности — модели не хватало поведенческих сигналов. Поначалу команда занималась ручной подстройкой ранжирования для новинок, но это не масштабировалось. К 2020 году Amazon представила подход Treating Cold Start in Product Search by Priors (WWW 2020): предсказание начальных поведенческих метрик через атрибуты товара — бренд, категорию, характеристики.
Alibaba разработала фреймворк AliBoost, который борется с эффектом «богатые становятся богаче»: популярные товары доминируют, а новинки остаются без показов. За полгода работы AliBoost «холодно запустил» более миллиарда товаров, увеличив клики и GMV «холодных» позиций на 60%.
eBay решает проблему прямолинейно: новые листинги получают временный буст видимости на 3–7 дней, в течение которых система собирает начальную статистику. Получил клики и продажи — закрепляешься. Нет — опускаешься.
Мы тоже используем и атрибутивные сигналы, и рекламные механизмы — но решили, что этого недостаточно. Нужно изменить сам объект, на котором живёт статистика. Не только подстраивать модель под неполные данные, но и дать ей правильные данные с самого начала.
Исторический контекст: жизнь на одном item_id
Исторически вся поведенческая статистика в поиске Ozon была привязана к item_id — уникальному идентификатору товара (то же, что SKU). У каждого товара был один большой «мешок», куда складывались просмотры, клики, добавления в корзину, заказы. Цена и срок доставки при этом жили только как фичи модели, но в ключ агрегации не входили. Пока мир вокруг статичен, это терпимо. Но в реальном маркетплейсе цены меняются (скидки, распродажи), логистика ускоряется или замедляется, в категорию постоянно приходят новинки. И тогда подход ломается. Возьмём конкретный пример.
Популярные кроссовки:
-
Полгода они стоили 10 000 ₽. Покупали вяло — низкий CTR, низкая конверсия. Система запомнила: «Этот товар так себе».
-
Продавец делает скидку 50%, цена становится 5 000 ₽. Это хит!
Проблема: система видит тот же самый item_id. Она смотрит в его историю и думает: «У него же плохая конверсия, зачем его поднимать?» Снижение цены обновилось в фичах, но самые весомые сигналы — исторические агрегаты — остались от «дорогого» товара. Это как оценивать ресторан по средней оценке за всё время, не различая, когда там работал великий шеф, а когда — студент-стажёр.
Три системные боли
-
Скидочная слепота. Снижение цены не давало мгновенного эффекта. Товар должен был неделями нарабатывать новую статистику по новой цене, чтобы перебить старый «дорогой» шлейф.
-
Холодный старт новинок. Новая модель кроссовок (0 заказов) всегда проигрывала старой (1 000 заказов), даже если объективно лучше по цене и доставке.
-
Логистика не учитывалась в статистике. Товар с доставкой «завтра» и тот же товар с доставкой «через неделю» копили историю в один мешок. Модель получала «среднюю температуру по больнице» и не могла поощрить быструю доставку.
Корень всех трёх проблем один: статистика привязана к товару, а не к его актуальному состоянию. Модель видела фичи «цена» и «доставка», но самые весомые сигналы — исторические агрегаты — были «слепы» к этому контексту.
На что опирается поиск: от первичных событий к фичам модели
Чтобы понять, почему проблема именно в уровне агрегации, стоит коротко описать, как устроены сигналы, которые получает модель ранжирования.
Всё начинается с первичных поведенческих событий: показ, клик, добавление в избранное, добавление в корзину, заказ. Из них мы собираем агрегаты за скользящие окна — и именно эти агрегаты становятся фичами модели. Модель не видит каждый отдельный клик — она видит «сколько кликов набрал этот объект за последние N дней». При этом мы строим два независимых набора признаков.
Товарные фичи агрегируют поведение по товару в целом: сколько просмотров, кликов, добавлений в корзину и заказов он получил за окно. Они отвечают на вопрос: «Насколько этот товар популярен на рынке?».
Парные фичи (запрос + товар) агрегируют поведение по паре «поисковый запрос — товар»: как часто именно по этому запросу пользователи кликали и заказывали именно этот товар. Они отвечают на вопрос: «Насколько этот товар релевантен конкретному запросу?».
Из этих агрегатов модель вычисляет производные метрики — например, CTR (click-through rate) — как отношение кликов к показам. Но CTR — это функция от первичных счётчиков. Если счётчики «слепы» к контексту (считают всё в один мешок по item_id, без учёта цены и доставки), то и CTR получается размытым. Модель видит «средний» CTR товара, в котором смешаны периоды высокой и низкой цены, быстрой и медленной доставки. Именно поэтому недостаточно просто добавить цену и доставку как отдельные фичи — модель их видит, но самые весомые сигналы (исторические агрегаты и производные от них) остаются привязаны к item_id и не чувствуют контекст.
Значит, чтобы модель по-настоящему «увидела» скидку или быструю доставку, нужно менять не алгоритм, а уровень, на котором считаются эти агрегаты. Нужна такая единица агрегации, при которой CTR кроссовок за 5 000 ₽ и CTR тех же кроссовок за 10 000 ₽ — это два разных CTR. И парная конверсия по запросу «кроссовки недорого» не смешивается между ценовыми сегментами.
Наше решение: две идеи, которые изменили всё
Идея 1. offer_id — «паспорт состояния» товара
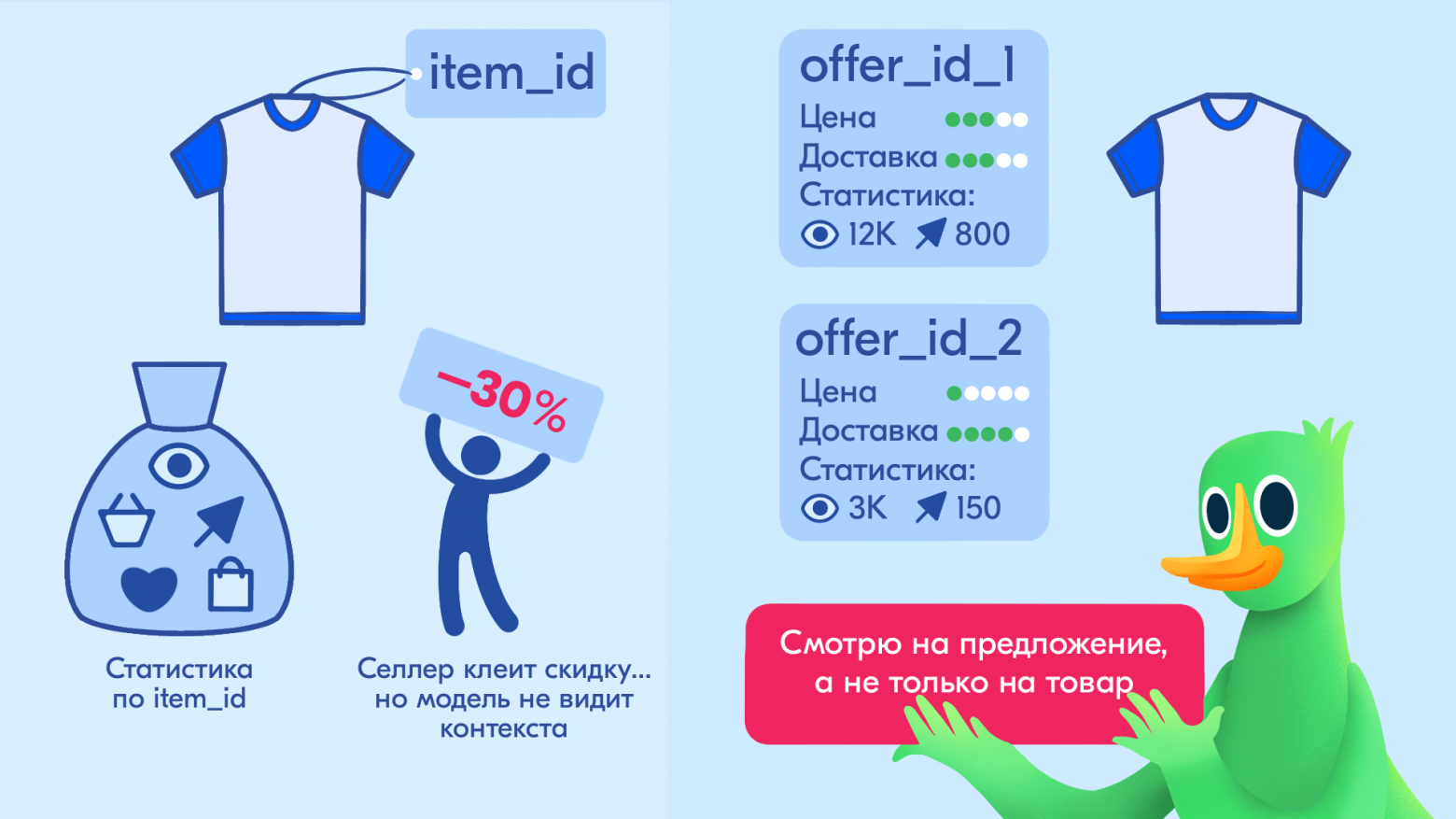
Если item_id — это ответ на вопрос «что продаём?», то нам нужна сущность, которая отвечает на вопрос «как продаём это прямо сейчас?». Мы назвали её offer_id.
Для каждого товара мы ежедневно определяем два параметра.
Ценовой сегмент (price_bin, 0–9). Мы берём все товары того же типа (например, все кроссовки) за 28 дней и считаем 9 децилей их цен — получаем 10 сегментов. Каждый товар попадает в свой бин: 0 — самые дешёвые 10% категории, 9 — самые дорогие.
Сегмент скорости доставки (delivery_bin, 0–9). Та же логика, но по срокам доставки внутри типа. 0 — самые быстрые, 9 — самые медленные.
Склеиваем item_id, price_bin и delivery_bin — получаем offer_id.

Меняется цена — меняется price_bin — меняется offer_id — меняется контекст, в котором модель принимает решение.
Для системы кроссовки за 10 000 ₽ и те же кроссовки за 5 000 ₽ — это теперь два разных предложения одного товара, каждое со своей статистикой.
Теоретически один товар может пройти через 100 состояний (10 × 10 комбинаций бинов). На практике у большинства товаров активны 2–5 состояний за жизненный цикл.
Иначе говоря, мы научили систему официально признавать: «Да, это тот же товар, но уже другое предложение».
Идея 2. Матрица W — шеринг истории между состояниями
У товара новый offer_id. Но что делать с историей?
-
Обнулить — потеряем ценные данные. Товар снова стартует с нуля.
-
Перенести 100% — притащим шлейф старого состояния, который уже не соответствует реальности.
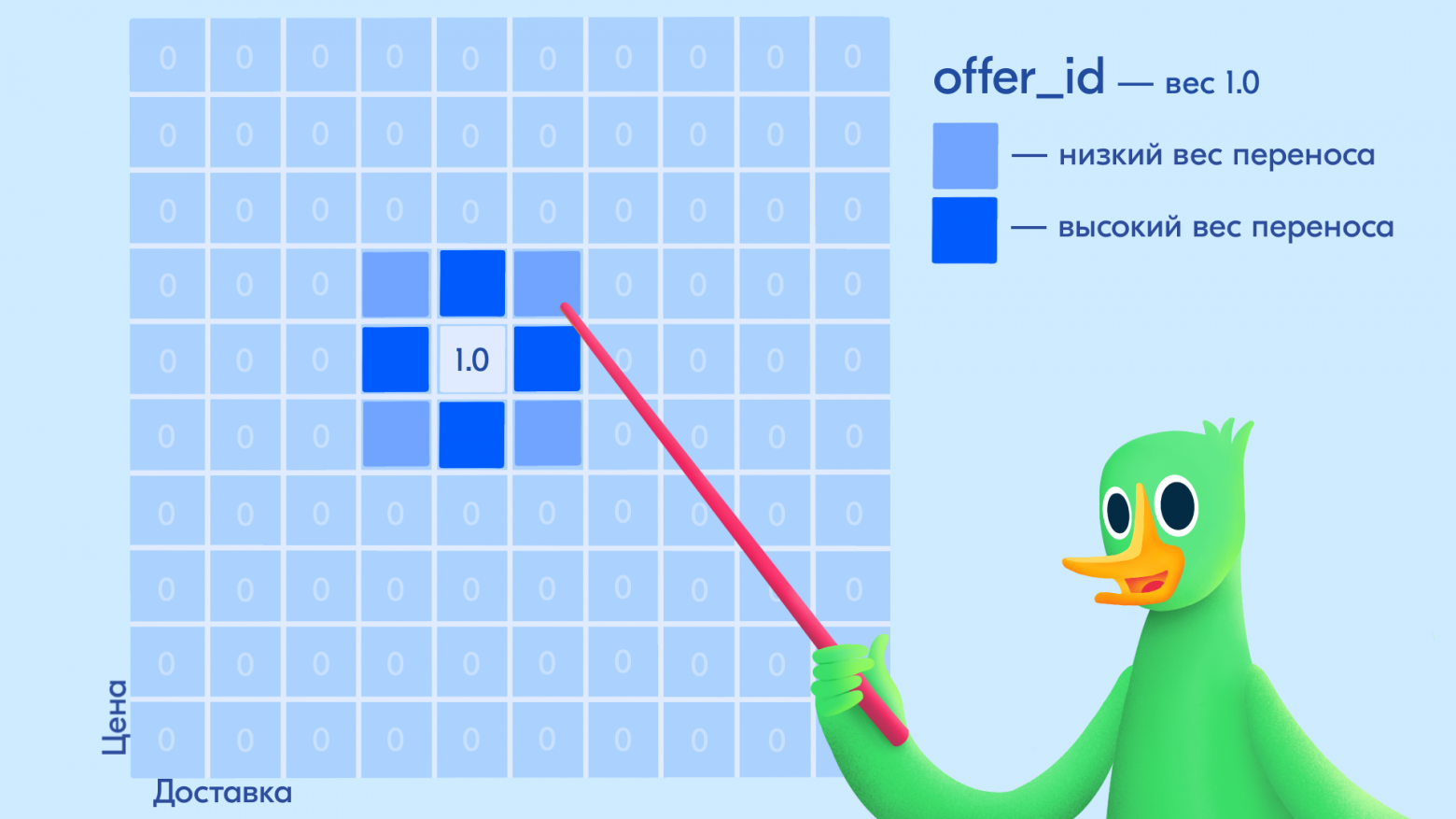
Нужна золотая середина. Для этого мы ввели матрицу близости W — компактную матрицу размером 100 × 100 (10 price_bins × 10 delivery_bins). Каждая ячейка

отвечает на вопрос: «Если товар был в состоянии (price_bin=i, delivery_bin=j), какую долю его статистики можно перенести в текущее состояние (price_bin=m, delivery_bin=n)?»
Принцип работы — на кроссовках:
Близкие соседи. Кроссовки подешевели на 5% — сдвиг на 1 бин. Матрица говорит: «Контекст почти не изменился, переносим ~90% статистики». Покупательское поведение при 10 000 ₽ и 9 500 ₽ практически одинаково.
Дальние соседи. Кроссовки подешевели вдвое — скачок на 3 бина. Матрица: «Старая статистика частично релевантна, берём ~30%». При 5 000 ₽ их покупают по другим мотивам, чем при 10 000 ₽.
Чужие. Товар из бина 9 (премиум) переехал в бин 0 (бюджет). Вес переноса близок к нулю — опыт премиальных продаж бесполезен для бюджетного сегмента.
Формально:

Или в матричной записи:

где 100 = 10 price_bins × 10 delivery_bins, а 5 метрик — это просмотры, клики, добавления в избранное, добавления в корзину и заказы. В результате взвешенного суммирования абсолюты становятся дробными (3,7 клика, 0,4 заказа). Для ML-модели это не проблема — она работает с плотностями вероятности, а не со счётчиками.
Матрицу W мы получаем эмпирически, анализируя, как изменение цены и доставки влияет на поведение пользователей. Коэффициенты затухания — настраиваемые параметры. Матрица единая для всей системы.
Для новинок — киллер-фича. Матрица W работает не только между состояниями одного товара, но и между разными товарами в одной группе аналогов. Ниже — два сценария, в которых это критически важно.
Сценарий 1: одинаковый товар от разных продавцов
У нас есть механизм матчинга, который автоматически определяет: «Это один и тот же продукт, просто от разных селлеров». Такие товары объединяются в группу, и матрица W работает внутри неё.
Покажем на примере. Три продавца выставляют одну и ту же модель робота-пылесоса Xiaomi X10:
|
Продавец |
Цена |
Доставка |
Заказы за месяц |
|---|---|---|---|
|
Продавец А |
25 000 ₽ |
2 дня |
500 |
|
Продавец Б |
23 000 ₽ |
1 день |
200 |
|
Продавец В (новичок) |
21 000 ₽ |
1 день |
0 |
Матчер определил, что все три карточки — один и тот же пылесос. Продавец В только вышел на площадку: лучшая цена, быстрая доставка, но ноль истории. В старой системе он стартовал бы с пустыми агрегатами и проигрывал конкурентам с сотнями заказов. Теперь матрица W берёт взвешенную статистику от продавцов А и Б (из той же группы, в соседних ценовых бинах) и передаёт новичку. Продавец В сразу получает начальный рейтинг, соответствующий ожиданиям покупателей от этого конкретного пылесоса в его ценовом сегменте.
Матчинг — один из механизмов формирования групп аналогов, но не единственный. О других подходах расскажем в следующей статье.
Сценарий 2: новый товар в категории
Вернёмся к нашему роботу-пылесосу с начала статьи — но теперь это не копия существующего товара, а принципиально новая модель. Матчер не нашёл точных дубликатов. У пылесоса нет собственной истории, и прямых аналогов от других продавцов тоже нет.
Но в категории «Робот-пылесос» десятки товаров в близких ценовых бинах с похожей доставкой. Матрица W «дарит» новинке взвешенную статистику этих соседей по категории — не 100%, а ровно столько, сколько релевантно для текущего состояния. Новинка стартует не с чистого листа, а с начальным рейтингом, соответствующим ожиданиям пользователей от товаров такой цены и скорости доставки.
Жизненный цикл offer_id: Init и Update
Вся эта история живёт в ежедневном пайплайне на Spark, но важна не столько конкретика таблиц, сколько общая механика. Нам нужно регулярно пересчитывать offer_id и статистику так, чтобы быть свежими, не разориться по ресурсам и не трясти выдачу каждый день.
Мы разделили жизнь системы на два режима.
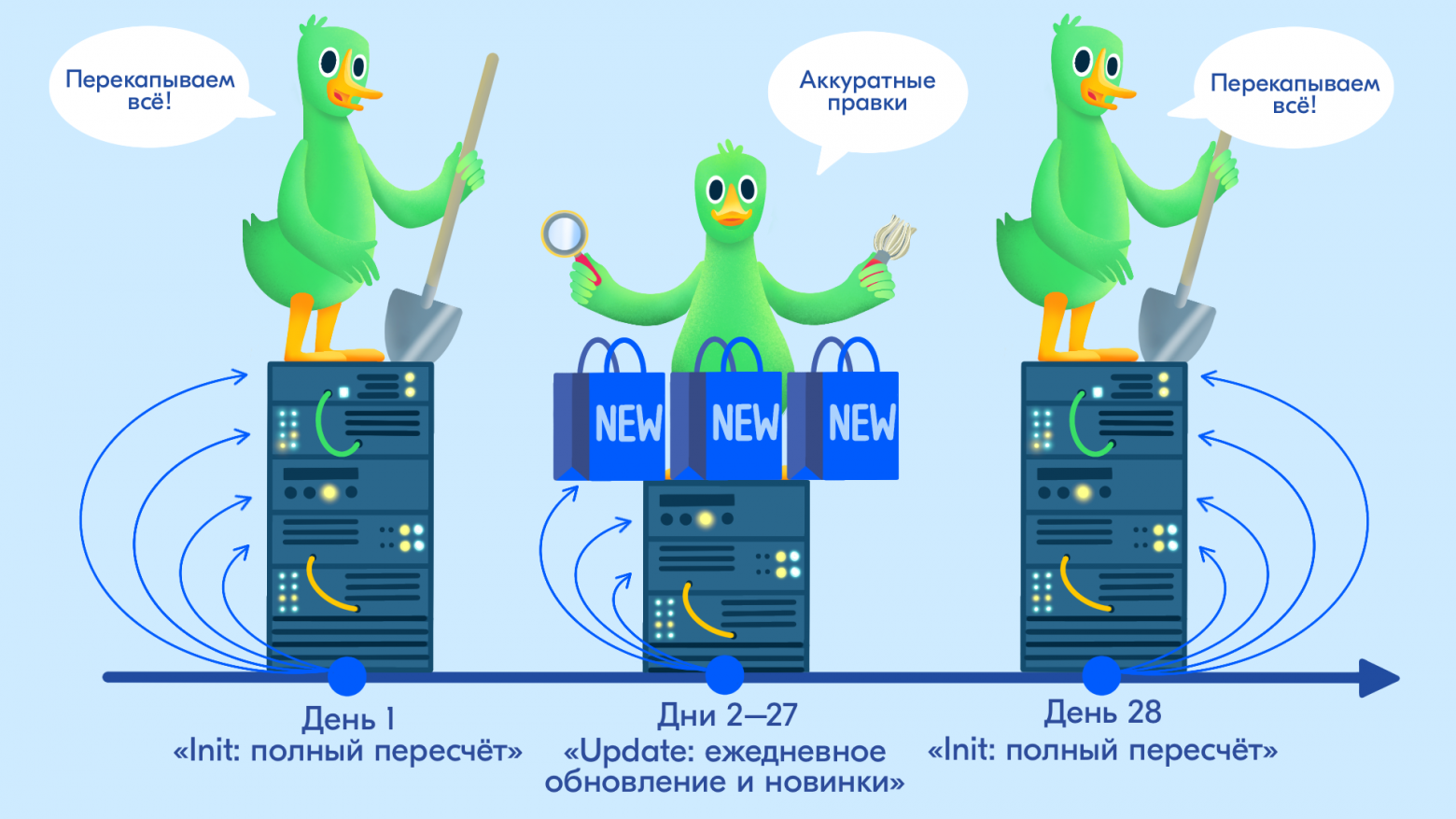
Init-дни: большая стирка раз в 28 дней
Примерно раз в 28 дней запускается тяжёлый пересчёт:
-
считаем свежие децильные пороги цен и сроков доставки по каждому типу товара за скользящее окно в 28 дней;
-
обновляем границы бинов;
-
полностью пересчитываем
offer_idи поведенческую статистику; -
подхватываем новые товары, даже если у них ещё нет собственной истории, — через статистику аналогов.
После Init у нас есть консистентная картина по всему ассортименту — как будто всю витрину прогнали через большую стиральную машину и аккуратно развесили по новым «верёвкам» бинов.
Update-дни: лёгкий ежедневный режим
Во все остальные дни запускается более лёгкий сценарий:
-
учитываем новые товары, которые появились за сутки;
-
обновляем статистику для активных
offer_id; -
инкрементально добавляем свежие поведенческие события.
То есть Init задаёт новую систему координат, а Update поддерживает её в живом состоянии, не дожидаясь следующей «генеральной уборки».
Сглаживание, чтобы выдача не дёргалась
Каждый Init двигает медианы и границы бинов. Если реагировать на малейший шум, товары начнут прыгать между бинами, а выдача — дёргаться, как курс валют во время новостей. Чтобы этого избежать, мы добавили сглаживающую логику:

где

Суть: сдвиг на 1 бин — остаёмся на месте, это шум. Сдвиг на 2+ — двигаемся, но только на один шаг за цикл. В итоге модель видит реальное движение рынка, а не каждый микрошум в медиане.
Если свести к одной фразе: Init — это редкая «перепрошивка мира», а Update — ежедневные патчи, которые не дают витрине застаиваться и в то же время не заставляют её дёргаться каждый день.
Новинки против старожилов: как offer_id решил проблему холодного старта
Интуитивно главными бенефициарами новой схемы должны были стать именно новинки — товары, которые сталкиваются с классической проблемой холодного старта (cold-start). У них нет собственной истории поведенческих событий, поэтому они безнадёжно проигрывают «старичкам» с тысячами заказов. Теперь, благодаря offer_id и матрице W, часть сигнала можно корректно «занять» у похожих товаров и дать новинке шанс быть просмотренной сразу после старта.
Что мы замерили до запуска
Перед запуском A/B-теста мы провели ретроспективный анализ:
-
Выделили товары, которые попали в индекс менее двух недель назад.
-
Оставили среди них только те, у которых уже была хоть какая‑то активность — просмотры, клики, заказы.
-
Посчитали baseline: как часто такие новинки получают трафик и конверсии в старой системе.
Что стало после внедрения
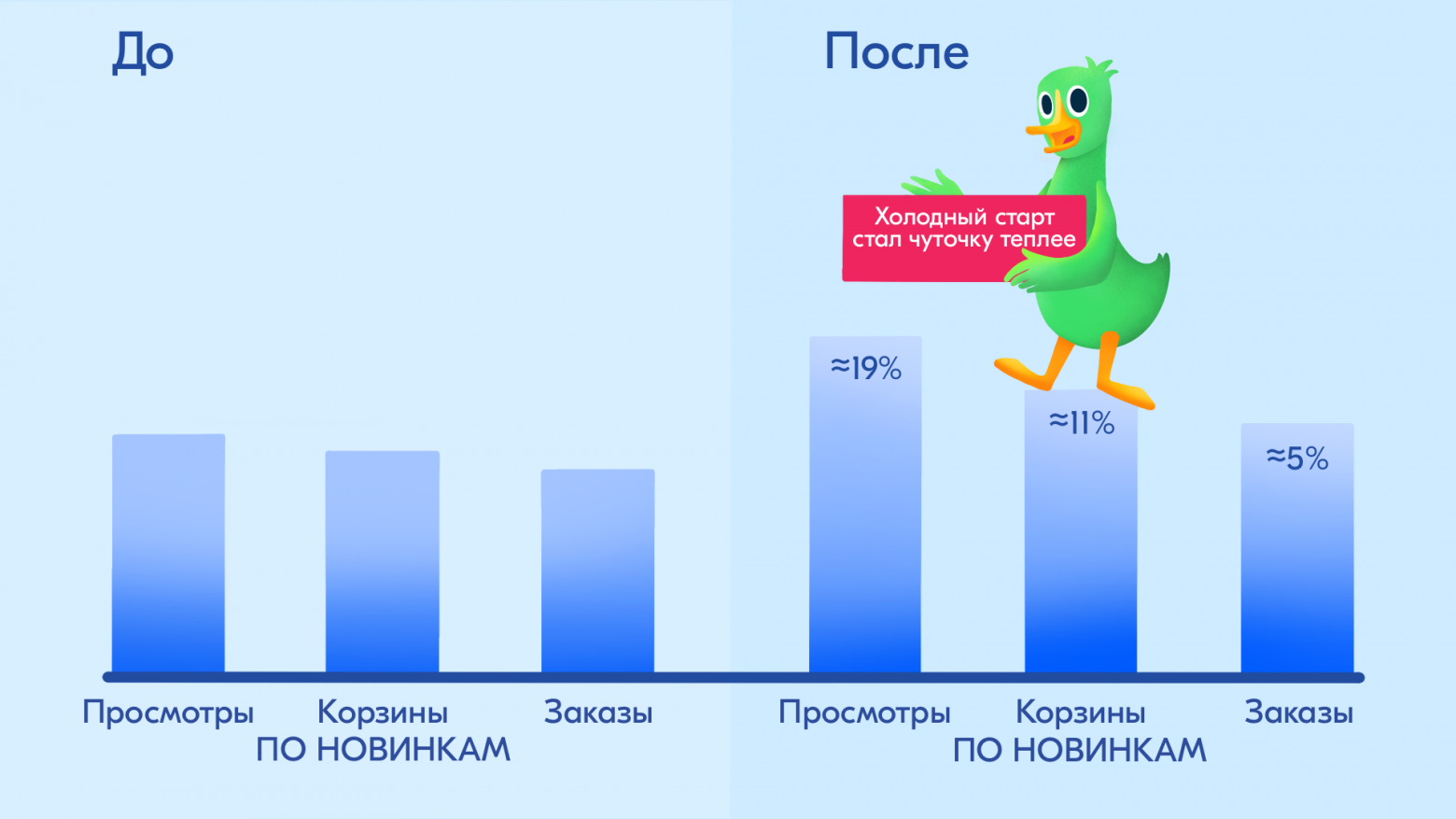
Цифры подтвердили гипотезу. После включения фич на базе offer_id для новых товаров мы увидели заметный рост:
-
заказы новинок: +5%;
-
добавления в корзину новинок: +11%;
-
просмотры карточек новинок: +19%.
Для товаров, добавленных в последнюю неделю, эффект оказался ещё сильнее: они чаще доходят до корзины и заказа. При этом среднее время до первого взаимодействия практически не изменилось: мы не вытаскиваем новинки искусственно в топ, а просто даём им больше валидных возможностей быть увиденными.
Параллельно с этим выросла доля новинок в общих метриках маркетплейса:
-
доля заказов новинок от всех заказов: +3,6%;
-
доля добавлений в корзину: +4,9%;
-
доля просмотров: +4,4%.
На уровне глобальных бизнес-метрик два последовательных A/B‑теста показали:
-
рост конверсии из поисковой сессии в заказ: +0,4%;
-
рост среднего GMV на пользователя: +0,9%.
Главный вывод из цифр: для новинок offer_id — это способ не начинать жизнь с чистого листа, а сразу занять место рядом с похожими, но уже проверенными предложениями.
Итоги для бизнеса, селлеров и планы на будущее
Для бизнеса:
-
Прирост на 0,9% к GMV на пользователя в масштабах Ozon.
-
Растёт вклад новинок в продажи.
-
Появляется гибкая архитектура: матрицу W можно адаптировать под разные категории, а логику пересчёта бинов — донастраивать.
Для селлеров:
-
Снижение цены и улучшение доставки быстрее отражаются на позициях в поиске.
-
Новые товары перестают быть «невидимками» и получают шанс конкурировать с карточками, имеющими многолетнюю историю.
-
Улучшение условий доставки быстрее отражается в ранжировании — быстрая и медленная доставка больше не смешиваются в одну статистику.
Для инженеров:
Для нас это важный урок архитектуры ML-систем: иногда, чтобы заметно сдвинуть качество ранжирования, не нужно изобретать новый сложный алгоритм. Достаточно правильно выбрать уровень агрегации, на котором живёт статистика, и научиться аккуратно переносить её между состояниями.
Если вы делаете поиск, рекомендации или любые системы, где контекст меняется быстрее, чем копится статистика, — возможно, вам тоже пора завести свой offer_id и свою матрицу близости. Гоша одобряет.
Если отбросить детали реализации, вся история — про одно наблюдение: иногда, чтобы сделать ранжирование менее смещённым и более прибыльным, не нужен новый модный алгоритм, достаточно правильно выбрать, на что вы вообще смотрите.
P. S. В заключение хочу поблагодарить Кирилла Ликсакова, руководителя команды Research-проектов поиска Ozon, за исходную идею проекта и архитектурные обсуждения, которые во многом определили направление решения, а также всю команду поиска за сотрудничество и помощь в создании статьи.
Источник
Вам также может быть интересно

Zap Africa сокращает 44% сотрудников в рамках реструктуризации на основе ИИ

45 000 лет на обучение Dota 2: Почему современный AI — это просто эффективная зубрежка
