

Matting Robustness: MaGGIe Performance Across Varying Mask Qualities
Table of Links
Abstract and 1. Introduction
-
Related Works
-
MaGGIe
3.1. Efficient Masked Guided Instance Matting
3.2. Feature-Matte Temporal Consistency
-
Instance Matting Datasets
4.1. Image Instance Matting and 4.2. Video Instance Matting
-
Experiments
5.1. Pre-training on image data
5.2. Training on video data
-
Discussion and References
\ Supplementary Material
-
Architecture details
-
Image matting
8.1. Dataset generation and preparation
8.2. Training details
8.3. Quantitative details
8.4. More qualitative results on natural images
-
Video matting
9.1. Dataset generation
9.2. Training details
9.3. Quantitative details
9.4. More qualitative results
8.3. Quantitative details
We extend the ablation study from the main paper, providing detailed statistics in Table 9 and Table 10. These tables offer insights into the average and standard deviation of performance metrics across HIM2K [49] and M-HIM2K datasets. Our model not only achieves competitive average results but also maintains low variability in performance across different error metrics. Additionally, we include the Sum Absolute Difference (SAD) metric, aligning with previous image matting benchmarks.
\ Comprehensive quantitative results comparing our model with baseline methods on HIM2K and M-HIM2K are presented in Table 12. This analysis highlights the impact of mask quality on matting output, with our model demonstrating consistent performance even with varying mask inputs.
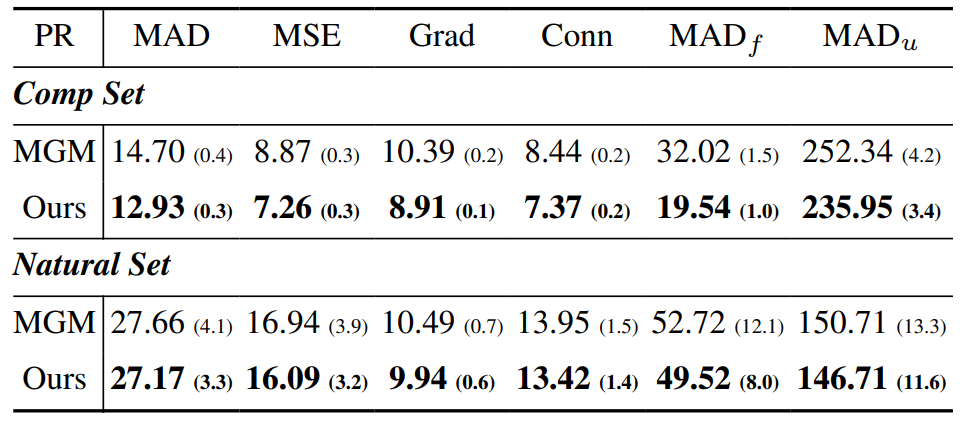
\ We also perform another experiment when the MGMstyle refinement replaces our proposed sparse guided progressive refinement. The Table 11 shows the results where our proposed method outperforms the previous approach in all metrics.
\ 
\ 
\
:::info Authors:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info This paper is available on arxiv under CC by 4.0 Deed (Attribution 4.0 International) license.
:::
\
You May Also Like

Trading time: Tonight, the US GDP and the upcoming non-farm data will become the market focus. Institutions are bullish on BTC to $120,000 in the second quarter.

United States CFTC Gold NC Net Positions rose from previous $204.6K to $2239K